Managing your machine learning infrastructure as code with Terraform
Let's say you want to deploy a recommender system at your company. A typical architecture might include a set of inference servers to run your embedding and ranking models, an approximate nearest neighbor index to select a set of candidate items that match your query, a database to retrieve features

Let's say you want to deploy a recommender system at your company. A typical architecture might include a set of inference servers to run your embedding and ranking models, an approximate nearest neighbor index to select a set of candidate items that match your query, a database to retrieve features about your selected candidate items, and a server that runs some business logic and filters your set of candidate items. These servers, databases, and the networking configurations that allow them to communicate with each other comprise the infrastructure of your machine learning system.
In this blog post, I'll provide an introduction to Terraform and how you can use it to provision the infrastructure layer of a machine learning system.
Overview
- What is infrastructure as code?
- Benefits of infrastructure as code
- A conceptual introduction to Terraform
- Typical workflow deploying infrastructure with Terraform
- Managing ML infrastructure with Terraform
- Best practices
- Design guide for creating modules
- Debugging
- Resources
What is infrastructure as code?
Terraform and similar infrastructure-as-code tools (CloudFormation, Pulumi, etc.) provide a mechanism for declaratively defining your infrastructure via a set of configuration files. This allows us to focus on what infrastructure we want to deploy (e.g. three servers with a load balancer) without needing to worry about how to provision these resources (e.g. first spin up three servers, then create a load balancer, then attach the servers to the load balancer).
These configuration files are stored in a version-controlled code repository which enables the same set of collaboration patterns that we already follow as part of the software development lifecycle. For example, if you wanted to propose changes to your team's infrastructure, you might create a new branch, update the relevant configuration files, and open a pull request to be reviewed by your team.
Benefits of infrastructure as code
When you first started working with cloud services, you probably just created whatever resources you needed directly in the AWS/GCP/Azure console. However, as the size of your organization or the number of projects grow, this becomes difficult to manage at scale.
Infrastructure-as-code tools simplify your life in a number of ways:
- Easier to keep track of resources. You don’t have to remember which resources you spun up for a given project, it’s all tracked in a centralized location. Spin up/down resources for a project with a single command.
- Create an audit log of changes to your infrastructure over time. By tracking our desired infrastructure state as code in a git repository, we can easily see how our infrastructure has evolved and query for the desired infrastructure state at a specific point in time.
- Repeatable across multiple environments. Creating reusable components helps ensure that your development environment accurately mirrors your production environment.
- Automation improves efficiency and reliability. By codifying how we provision and manage infrastructure for our projects, we can reduce the potential for human error.
A conceptual introduction to Terraform
Let's first spend some time to discuss the common set of abstractions in Terraform's design that allows us to flexibly create infrastructure for whatever configuration we might need.
Terraform communicates with a wide variety of infrastructure providers which are responsible for creating, updating, and deleting the set of resources that we use to deploy our applications.
Terraform has providers for generic cloud infrastructure companies (e.g. AWS, GCP, Azure) as well as more focused, higher-level infrastructure services (e.g. Auth0, DataDog, Snowflake, and many more). If you happen to come across an infrastructure component that isn't already available via Terraform's registry of providers, you can always create your own provider as long as there's an API you can communicate with to create, read, update, and delete resources.
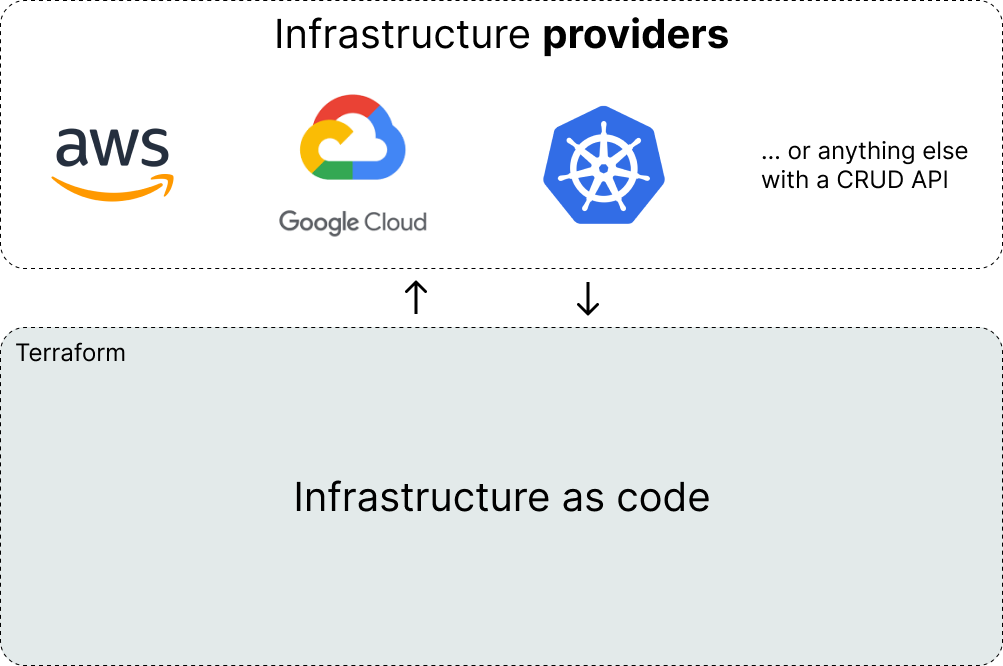
A resource is the smallest unit of infrastructure managed by a given provider; each provider will have a different set of documented resources supported for you to deploy. For example, using the AWS provider you can spin up an EC2 machine (server) or an RDS database. Using the Snowflake provider, you can configure your data warehouse. These are just a few examples, each provider's documentation page will list the full set of available resources.
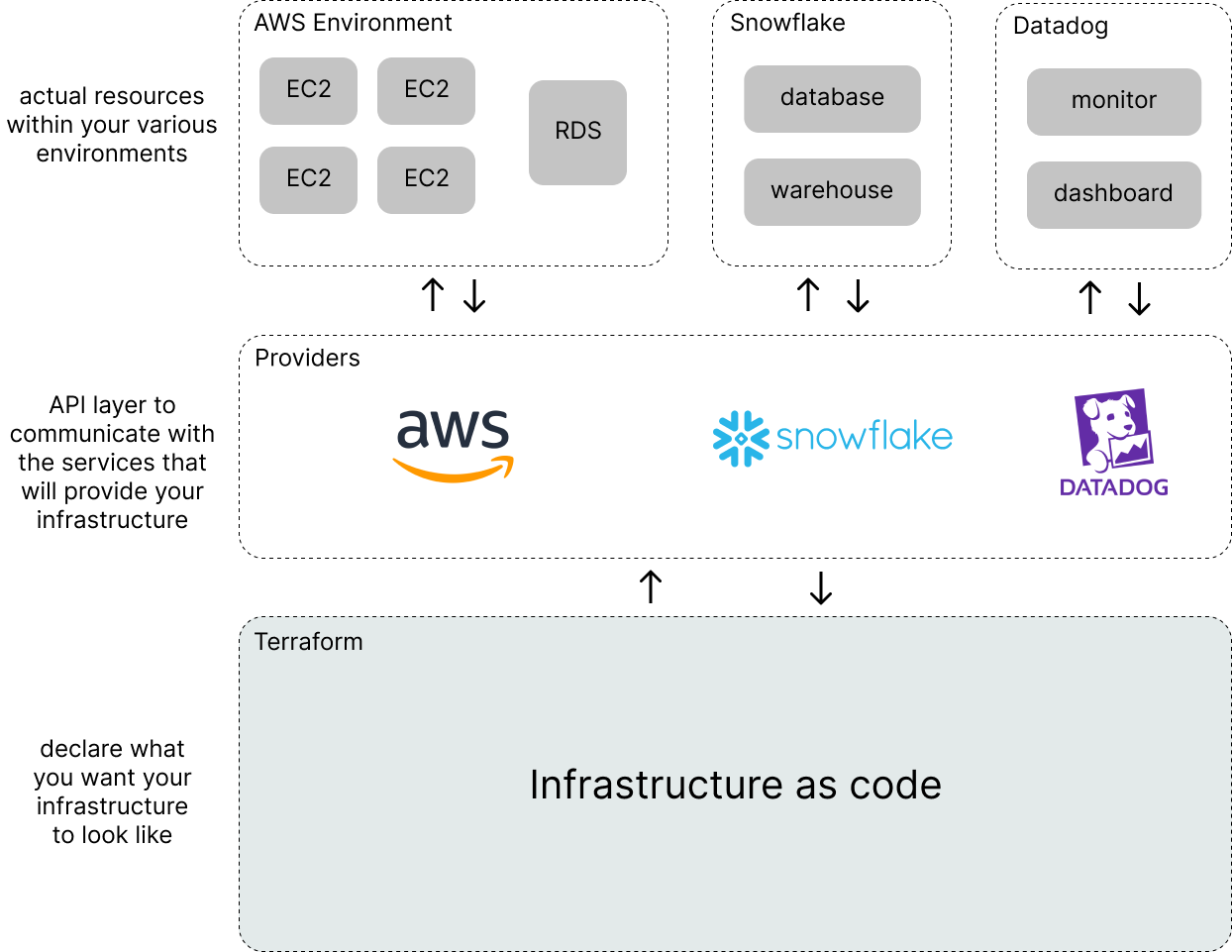
Let's take a look at a minimal example of a Terraform configuration to see what this looks like in practice.
provider "aws" {
region = "us-west-2"
}
resource "aws_instance" "my_example_server" {
ami = "ami-005e54dee72cc1d00"
instance_type = "t2.micro"
tags = {
name = "example"
owner = "jeremy"
}
}Here, we're using the AWS provider to configure a single EC2 instance. We could save this configuration as a file named main.tf, run terraform apply, and Terraform would get to work reading in your AWS credentials and communicating with AWS to spin up our requested instance. We'll revisit this process for actually spinning up/down resources in the next section, but there's a few more Terraform concepts that I want to cover first.
The above example looks pretty simple, but it's likely that you'll need to provision more than a single EC2 instance for your infrastructure needs. I mean, have you seen how many different services AWS puts in their reference architecture diagrams?
Terraform modules allow us to group together common resources, making it easier to reuse across projects or environments. A module is defined as a folder or directory containing one or more Terraform files (e.g. files with the .tf extension) which specify a set of providers and resources that we'd like to deploy. In order to facilitate module reuse, we can define variables to flexibly configure certain resource attributes and outputs to provide useful information that other resources/modules may need to know about.

As an example, suppose we want to standardize how servers are provisioned at our company. We can do this with Terraform by creating a terraform-cloud-server module which uses a (fictitious) cloud provider to create some example resources.
We'll define two resource specifications:
- a web server which always uses Linux as the operating system
- a log stream which retains the server's log output for 90 days
resource "cloud_server" "server" {
operating_system = "linux"
memory = var.server_memory
cpus = var.server_cpus
log_stream = cloud_log_stream.logs.id
}
resource "cloud_log_stream" "logs" {
name = "${var.project}_log_stream"
retention_in_days = 90
}In this scenario, operating_system and retention_in_days will be consistent across all of the servers created using this module. However, we still may want to configure some values, such as the server memory, depending on the requirements of each individual server. For these values, we can create variables to pass configuration from the module level to individual resources within the module (as seen above).
variable "project" {
description = "Provide a unique name for your project"
type = string
}
variable "server_cpus" {
description = "Number of CPUs requested for the server"
type = number
default = 2
}
variable "server_memory" {
description = "Amount of memory requested for the server"
type = string
default = "4 GiB"
}And finally, we may want to know some information about the low-level resources that are created as part of this terraform-cloud-server module. We can expose this information by specifying outputs.
output "server_ip_address" {
description = "IP address for the server"
value = cloud_server.server.ip_address
}Putting this all together, our Terraform module would look something like:
├── terraform-cloud-server
├── README.md
├── main.tf
├── outputs.tf
└── variables.tfIf we wanted to use this module in our infrastructure configuration, we'd define a module block which specifies where our module is defined and provides all of the necessary variables to configure the underlying resources.
module "standard_server" {
source = "../path/to/terraform-cloud-server"
server_cpus = 4
server_memory = "8 GiB"
}In some cases, you may want to query information from a given provider when configuring a resource. For example, suppose we want to use an existing IP network (and its corresponding configuration) when assigning an IP address to our cloud server. A data resource allows you to query a given provider for information about existing components that might be useful when configuring new resources in your module.
data "vpc" "selected" {
id = var.vpc_id
}
# e.g. use the data resource when configuring other resources
resource "cloud_server" "server" {
...
subnet = data.vpc.selected.private_subets[0]
}Putting this all together, we can see that our infrastructure as code is largely comprised of modules (reusable groups of resource definitions) and configurations (a specification of the resources/modules that we want to deploy in a given environment).
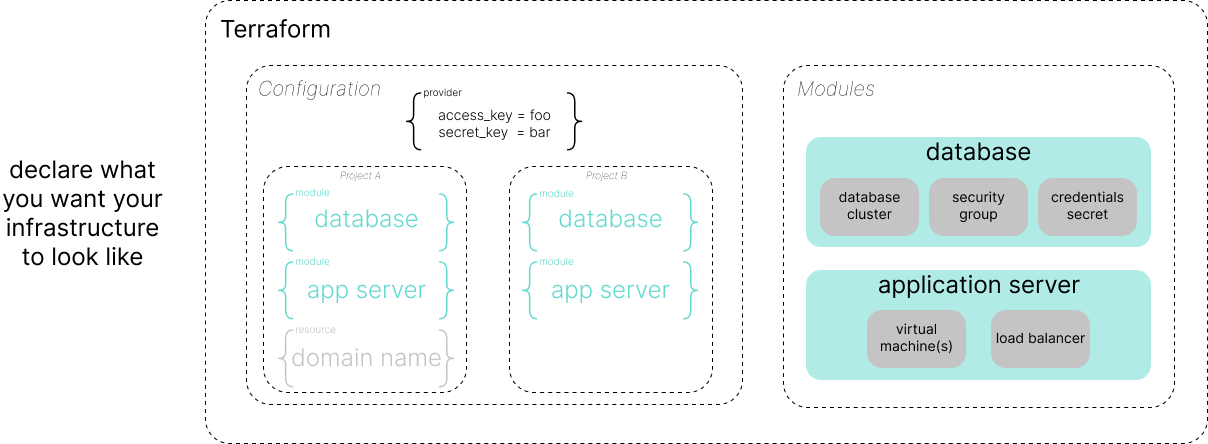
Note: the "modules" and "configurations" that I refer to above are both technically Terraform modules, since a module is just a directory of Terraform files, but I find it useful to draw a distinction between the two groups since they each have a different intention.
Typical workflow deploying infrastructure with Terraform
Now that we've covered the basic concepts, let's walk through the standard workflow for deploying your infrastructure with Terraform.
Specify your desired state
The first step is to specify the collection of resources (and modules) that you want to provision. We do this by defining a series of configuration blocks in one or more Terraform files within the same directory.
For more details on how to specify these configuration blocks, you can either review the Terraform documentation (more likely to be up-to-date over time) or check out the Terraform configuration: quick reference that I put together.
Building on the previous example using the (fictitious) cloud provider, a configuration for project_a might look something like:
module "database" {
source = "../path/to/terraform-cloud-database-module"
name = "project_a_database"
cpu_limit = 4
memory_limit = "16 GiB"
backup_daily = true
}
module "app_server" {
source = "../path/to/terraform-cloud-app-server-module"
replicas = 5
cpu_limit = 2
memory_limit = "1 GiB"
container_image = "my_org/project_a:latest"
}
resource "cloud_domain_name" "domain" {
name = "app.example.com"
target = module.app_server.load_balancer.ip_address
}Note: It's generally best to deploy your infrastructure as separate, logical components rather than one giant pile of Terraform configurations. This enables you to create/destroy resources for project_a without having any affect on project_b's resources.
terraform/
configuration/
development/
staging/
production/
account_base/
main.tf # resources you only need to create once per environment
region_a/
region_base/
main.tf # resources you only need to create once per region
project_a/
main.tf # project-specific resources
project_b/
main.tf # project-specific resources
region_b/
...Build an execution plan
Once we've specified our desired infrastructure state, we'll run terraform plan from the same directory as our configuration files. Terraform will get to work communicating with the necessary providers in order to figure out the actual state of our infrastructure, how that differs from our desired state, and the set of changes we need to make in order to achieve our desired state.
Terraform will output this plan to the console, sharing the set of resources will get created, modified in place, or deleted if we execute the plan.
$ terraform plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# module.database.cloud_database_cluster.cluster will be created
+ resource "cloud_database_cluster" "cluster" {
+ id = (known after apply)
+ name = "project_a_database"
...
}
...
Plan: 10 to add, 0 to change, 0 to destroy.
In order for Terraform to know:
- which resources need to be created,
- which resources already exist and may simply need updated,
- and which resources are no longer necessary,
Terraform maintains a state file which describes a mapping between resources defined in our configuration and resources that exist in the real world. This state file also contains other useful metadata such as resource dependencies, which helps Terraform know which order to safely destroy resources which are no longer needed. Most teams will configure Terraform to save this state file in a remote data store (e.g. Amazon S3) so that there's a single source of truth. This also allows us to set up state file locking (e.g. keeping track of locks in a DynamoDB table) so that multiple people can't be updating the same set of resources at the same time.
Apply your execution plan
Once you've reviewed the plan and confirmed that it looks correct, you can run terraform apply to execute the plan described in the previous step. Terraform will then perform the following steps:
- Place a lock on the state file to prevent any other Terraform processes from modifying the same set of resources.
- Create a new execution plan, unless you explicitly provide the output of a
terraform planthat you ran previously. - Follow the above execution plan, leveraging the providers to create, update, and delete the appropriate resources in a safe order.
- Update the state file to reflect changes made to our set of resources.
- Remove the lock from the state file so that other Terraform processes can make changes when needed.
Clean up resources you're no longer using
Once we're ready to tear down the resources defined in your Terraform configuration, you can simply run terraform destroy from the same directory as our configuration files. Terraform will leverage its understanding of resource dependencies in order to delete the resources in a safe order.
Managing ML infrastructure with Terraform
Let's now walk through a standard machine learning model lifecycle and discuss how we might support the requisite infrastructure components with Terraform.
my generic mental model for the various components involved in operating a machine learning system. pic.twitter.com/CtL9sAGd6R
— Jeremy Jordan (@jeremyjordan) April 17, 2022
We'll need the ability to define a batch job which runs a training job for our model, so we'll go ahead and define a terraform-aws-batch-job module which can (1) be triggered either based on an event or a cron schedule, (2) spin up the necessary compute to train our model, (3) connect to the appropriate data sources for generating our training and validation datasets, and (4) spin down the necessary compute once our job completes.
This training job will need to log key metrics and output the trained model artifacts into a model registry. We'll probably need to create a database and a cloud object store to save model metadata and artifacts respectively.
Further, we might configure the model registry to automate a deployment rollout when a user updates a registered model's stage from shadow mode to production. This may make calls out to a service such as Sagemaker to update the model artifact being served at a given endpoint. In this case, we may create some of the initial Sagemaker infrastructure using Terraform but mark certain attributes as ignore_changes in the lifecycle block (see more on this below) in order to allow our model registry to dynamically update the model configuration.
Best practices
Generate documentation for your Terraform modules
In order to provide a succinct summary of the modules you create, you can use terraform-docs to automatically generate a description of a module's variables and outputs, in addition to the resources and modules it creates.
terraform-docs markdown table \
--output-file README.md \
--output-mode inject .Tag your resources
Some providers allow you to specify tags/labels for your resources as a method of organization. It's a good practice to leverage these tags to store information such as resource ownership, which projects a resource may belong to, how this resource should be categorized from a billing perspective, or other key information.
resource "resource_type" "resource_name" {
# resource-specific configuration
...
tags = {
Owner = "my-team"
Project = "my-project"
Environment = "development"
Billing = "some-cost-center"
}
}Monitor for drift between your desired and actual infrastructure states
Terraform only checks for discrepancies between the actual state and desired state of your infrastructure when you run commands. It's entirely possible that someone has made changes to your infrastructure outside of Terraform (e.g. manual actions in the AWS console), so the desired state that you track in a code repository isn't always an accurate depiction of what's deployed. It's usually a good practice to periodically check for "infrastructure drift"; you can use tools such as driftctl to automate this process.
In order to bring Terraform configuration back in line with reality:
- Run
terraform plan -refresh-onlyto compare Terraform’s state file with the actual current infrastructure - Update the configuration files to match the current state (assuming you want to keep the resources which were created outside of Terraform)
- Run
terraform importto update Terraform’s state file and associate the updated configuration with the already-created infrastructure
You can run terraform apply -replace="resource_type.resource_name" to target a specific resource to recreate in the event that someone manually changed its configuration.
Safeguard critical resources from accidental downtime
Some terraform apply plan executions can introduce the possibility of downtime, which may not always be ideal for resources that need to be highly available. The Terraform lifecycle block allows you to specify some degree of control over how resources can be updated.
resource "resource_type" "resource_name" {
lifecycle {
prevent_destroy = true # prevent accidental deletion of resources
create_before_destroy = true # avoid downtime when replacing a resource
ignore_changes = [attr] # ignore differences between config and state
}
} Design guide for creating modules
Modules are incredibly useful for deploying the same set of infrastructure components across projects, regions, or environments. The first rule of Terraform modules is that you should use them. There's a wide variety of ready-to-use Terraform modules developed by the community; it's likely that a module already exists for some of your infrastructure needs. However, it's also likely that you'll end up needing to build some Terraform modules that are more specific to how your company provisions infrastructure.
Here are some tips to keep in mind when building Terraform modules:
- Keep modules focused on a single purpose. Modules should be used to group a set of resources that are always deployed together.
- Group resources together that change at a similar frequency. By keeping short-lived resources separate from long-lived resources, we can reduce risk associated with making changes to our infrastructure.
- Consider the sensitivity of the infrastructure resources being grouped. A networking module might have a different set of security implications as compared to an application server module. It's best to keep highly privileged resources separate so that we can design with the principle of least access in mind.
- Take a hierarchical approach when designing modules. In order to get the most reuse out of your modules, it can be helpful to define a base set of modules which define lower-level infrastructure components which can then be referenced across a set of higher-level modules.
Debugging
There are a number of areas where things can go wrong when managing infrastructure with Terraform. Here are a few of those scenarios, as well as some quick tips for identifying and resolving issues.
You have syntax errors in your configuration files.
Run terraform fmt to surface syntax errors. You can also configure your IDE to run the formatter every time you save a file.
You may improperly configured some of your resources.
Run terraform validate to check your configuration in the context of the infrastructure provider. If you want to interactively test your configuration expressions, you can run terraform console.
Your state file has been corrupted.
Run terraform state list [options] [address] to inspect the state file for a given resource or module. Alternatively, you can run terraform show to view the entire state file.
Your state file has a stale lock.
Terraform uses state file locking in order to prevent multiple users from overwriting the same set of resources at the same time. For the S3 remote state configuration, you can configure a locking table with DynamoDB where Terraform will simply write some lock metadata to a specified key in your table (and remove it when the lock is released). If Terraform ends up in a weird state, you may need to manually remove this lock with terraform force-unlock.
There's a bug in a provider that you're using.
Capture logs from the providers when executing a plan or apply.
export TF_LOG_CORE=TRACE
export TF_LOG_PROVIDER=TRACE
export TF_LOG_PATH=logs.txtResources
Tutorials
- Official Terraform tutorials
- There's a lot of great content here, the only problem is it's a lot which is why I decided it might be useful to write a condensed introduction to Terraform (this blog post).
- HashiCorp - Recommended Enterprise Patterns
- Purpose of Terraform State
- Troubleshoot Terraform
- Terraform Best Practices: Key Concepts
Blog posts
Tools
- Terraform Provider Iterative (TPI)
- The team at iterative.ai has created a Terraform provider which makes it really easy to create the infrastructure needed for running ML tasks, including best practices by default such as using spot instances and spinning down resources once the task successfully finishes.
 jeremyjordan
jeremyjordanAcknowledgements
Thanks to Vicki Boykis, Jérémie Vallée, John Huffman, and Adam Laiacano for reading early drafts of this blog post and providing helpful feedback.