An introduction to Kubernetes.
This blog post will provide an introduction to Kubernetes so that you can understand the motivation behind the tool, what it is, and how you can use it. In a follow-up post, I'll discuss how we can leverage Kubernetes to power data science workloads using more concrete (data science) examples.

This blog post will provide an introduction to Kubernetes so that you can understand the motivation behind the tool, what it is, and how you can use it. In a follow-up post, I'll discuss how we can leverage Kubernetes to power data science workloads using more concrete (data science) examples. However, it helps to first build an understanding of the fundamentals - which is the focus of this post.
Prerequisites: I'm going to make the assumption that you're familiar with container technologies such as Docker. If you don't have experience building and running container images, I suggest starting here before you continue reading this post.
Overview
Here's what we'll discuss in this post. You can click on any top-level heading to jump directly to that section.
- What is the point of Kubernetes?
- Design principles.
- Declaritive
- Distributed
- Decoupled
- Immutable
- Basic objects in Kubernetes.
- Pod
- Deployment
- Service
- Ingress
- Job
- How? The Kubernetes control plane.
- Master node
- API server
- etcd
- scheduler
- controller-manager
- Worker nodes
- kubelet
- kube-proxy
- Master node
- When should you not use Kubernetes?
- Resources
What is the point of Kubernetes?
Kubernetes is often described as a container orchestration platform. In order to understand what exactly that means, it helps to revisit the purpose of containers, what's missing, and how Kubernetes fills that gap.
Note: You will also see Kubernetes referred to by its numeronym, k8s. It means the same thing, just easier to type.
Why do we love containers? Containers provide a lightweight mechanism for isolating an application's environment. For a given application, we can specify the system configuration and libraries we want installed without worrying about creating conflicts with other applications that might be running on the same physical machine. We encapsulate each application as a container image which can be executed reliably on any machine* (as long as it has the ability to run container images), providing us the portability to enable smooth transitions from development to deployment. Additionally, because each application is self-contained without the concern of environment conflicts, it's easier to place multiple workloads on the same physical machine and achieve higher resource (memory and CPU) utilization - ultimately lowering costs.
What's missing? However, what happens if your container dies? Or even worse, what happens if the machine running your container fails? Containers do not provide a solution for fault tolerance. Or what if you have multiple containers that need the ability to communicate, how do you enable networking between containers? How does this change as you spin up and down individual containers? Container networking can easily become an entangled mess. Lastly, suppose your production environment consists of multiple machines - how do you decide which machine to use to run your container?
Kubernetes as a container orchestration platform. We can address many of the concerns mentioned above using a container orchestration platform.
The director of an orchestra holds the vision for a musical performance and communicates with the musicians in order to coordinate their individual instrumental contributions to achieve this overall vision. As the architect of a system, your job is simply to compose the music (specify the containers to be run) and then hand over control to the orchestra director (container orchestration platform) to achieve that vision.

A container orchestration platform manages the entire lifecycle of individual containers, spinning up and shutting down resources as needed. If a container shuts down unexpectedly, the orchestration platform will react by launching another container in its place.
On top of this, the orchestration platform provides a mechanism for applications to communicate with each other even as underlying individual containers are created and destroyed.
Lastly, given (1) a set of container workloads to run and (2) a set of machines on a cluster, the container orchestrator examines each container and determines the optimal machine to schedule that workload. To understand why this can be valuable, watch Kelsey Hightower explain (17:47-20:55) the difference between automated deployments and container orchestration using an example game of Tetris.
Design principles.
Now that we understand the motivation for container orchestration in general, let's spend some time to discuss the motivating design principles behind Kubernetes. It helps to understand these principles so that you can use the tool as it was intended to be used.
Declarative
Perhaps the most important design principle in Kubernetes is that we simply define the desired state of our system and let Kubernetes automation work to ensure that the actual state of the system reflects these desires. This absolves you of the responsibility of fixing most things when they break; you simply need to state what your system should look like in an ideal state. Kubernetes will detect when the actual state of the system doesn't meet these expectations and it will intervene on your behalf to fix the problem. This enables our systems to be self-healing and react to problems without the need for human intervention.
The "state" of your system is defined by a collection of objects. Each Kubernetes object has (1) a specification in which you provide the desired state and (2) a status which reflects the current state of the object. Kubernetes maintains a list of all object specifications and constantly polls each object in order to ensure that its status is equal to the specification. If an object is unresponsive, Kubernetes will spin up a new version to replace it. If a object's status has drifted from the specification, Kubernetes will issue the necessary commands to drive that object back to its desired state.
Distributed
For a certain operating scale, it becomes necessary to architect your applications as a distributed system. Kubernetes is designed to provide the infrastructural layer for such distributed systems, yielding clean abstractions to build applications on top of a collection of machines (collectively known as a cluster). More specifically, Kubernetes provides a unified interface for interacting with this cluster such that you don't have to worry about communicating with each machine individually.
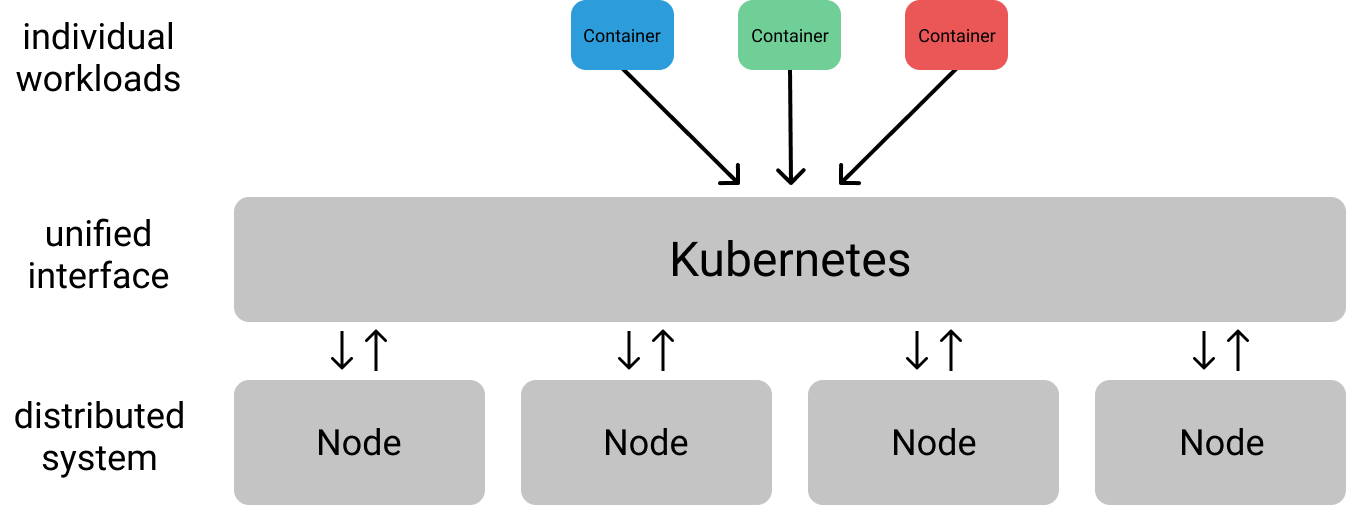
Decoupled
It is commonly recommended that containers be developed with a single concern in mind. As a result, developing containerized applications lends itself quite nicely to the microservice architecture design pattern, which recommends "designing software applications as suites of independently deployable services."
The abstractions provided in Kubernetes naturally support the idea of decoupled services which can be scaled and updated independently. These services are logically separated and communicate via well-defined APIs. This logical separation allows teams to deploy changes into production at a higher velocity since each service can operate on independent release cycles (provided that they respect the existing API contracts).
Immutable infrastructure
In order to achieve the most benefit from containers and container orchestration, you should be deploying immutable infrastructure. This is, rather than logging in to a container on a machine to make changes (eg. updating a library), you should build a new container image, deploy the new version, and terminate the older version. As you transition across environments during the life-cycle of a project (development -> testing -> production) you should use the same container image and only modify configurations external to the container image (eg. by mounting a config file).
This becomes very important since containers are designed to be ephemeral, ready to be replaced by another container instance at any time. If your original container had mutated state (eg. manual configuration) but was shut down due to a failed healthcheck, the new container spun up in its place would not reflect those manual changes and could potentially break your application.
When you maintain immutable infrastructure, it also becomes much easier to roll back your applications to a previous state (eg. if an error occurs) - you can simply update your configuration to use an older container image.
Basic objects in Kubernetes.
Previously, I mentioned that we describe our desired state of the system through a collection of Kubernetes objects. Up until now, our discussion of Kubernetes has been relatively abstract and high-level. In this section, we'll dig into more specifics regarding how you can deploy applications on Kubernetes by covering the basic objects available in Kubernetes.
Kubernetes objects can be defined using either YAML or JSON files; these files defining objects are commonly referred to as manifests. It's a good practice to keep these manifests in a version controlled repository which can act as the single source of truth as to what objects are running on your cluster.
Pod
The Pod object is the fundamental building block in Kubernetes, comprised of one or more (tightly related) containers, a shared networking layer, and shared filesystem volumes. Similar to containers, pods are designed to be ephemeral - there is no expectation that a specific, individual pod will persist for a long lifetime.

You won't typically explicitly create Pod objects in your manifests, as it's often simpler to use higher level components which manage Pod objects for you.
Deployment
A Deployment object encompasses a collection of pods defined by a template and a replica count (how many copies of the template we want to run). You can either set a specific value for the replica count or use a separate Kubernetes resource (eg. a horizontal pod autoscaler) to control the replica count based on system metrics such as CPU utilization.
Note: The Deployment object's controller actually creates another object, a ReplicaSet, under the hood. However, this is abstracted away from you as the user.
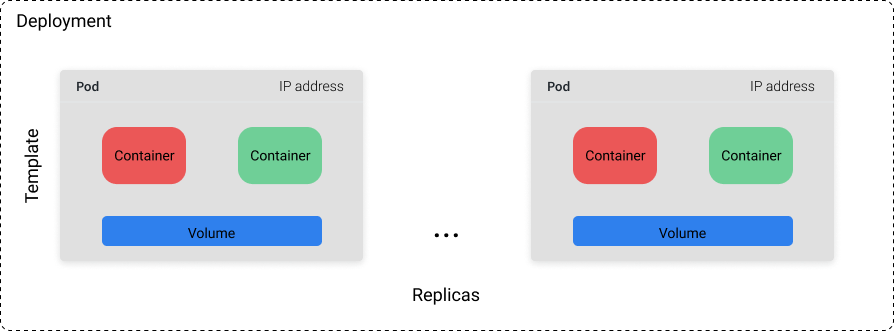
While you can't rely on any single pod to stay running indefinitely, you can rely on the fact that the cluster will always try to have $n$ pods available (where $n$ is defined by your specified replica count). If we have a Deployment with a replica count of 10 and 3 of those pods crash due to a machine failure, 3 more pods will be scheduled to run on a different machine in the cluster. For this reason, Deployments are best suited for stateless applications where Pods are able to be replaced at any time without breaking things.
The following YAML file provides an annotated example of how you might define a Deployment object. In this example, we want to run 10 instances of a container which serves an ML model over a REST interface.
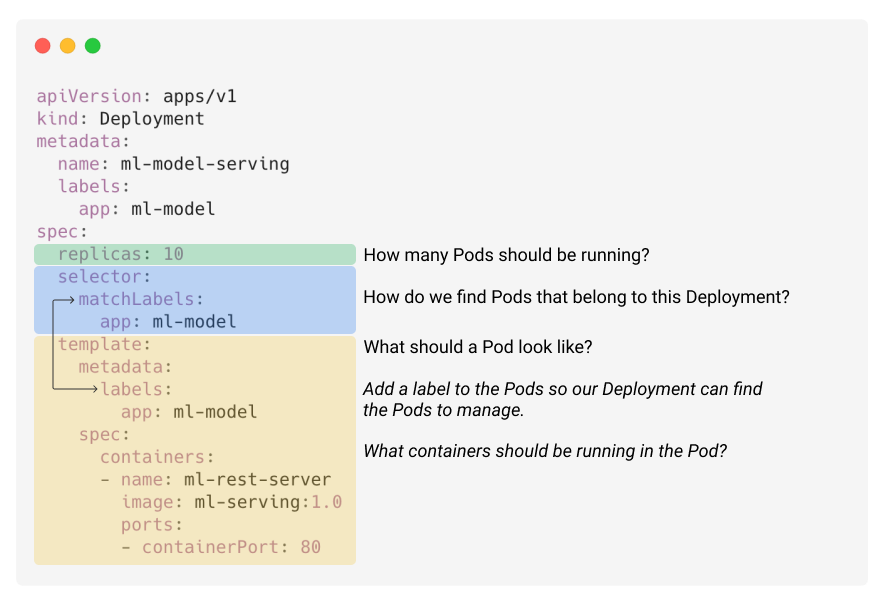
Note: In order for Kubernetes to know how compute-intensive this workload might be, we should also provide resource limits in the pod template specification.
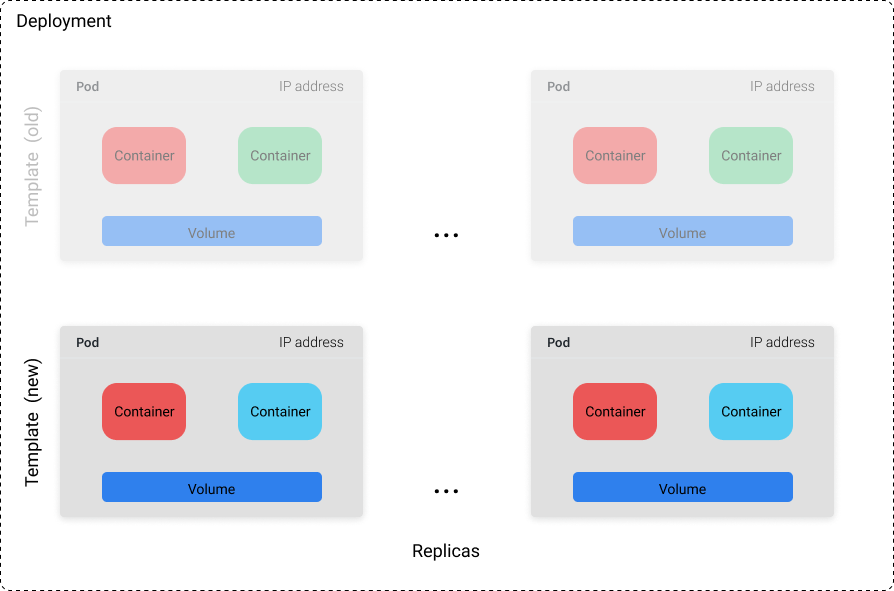
Deployments also allow us to specify how we would like to roll out updates when we have new versions of our container image; this blog post provides a good overview of your different options. If we wanted to override the defaults we would include an additional strategy field under the object spec. Kubernetes will make sure to gracefully shut down Pods running the old container image and spin up new Pods running the new container image.
Service
Each Pod in Kubernetes is assigned a unique IP address that we can use to communicate with it. However, because Pods are ephemeral, it can be quite difficult to send traffic to your desired container. For example, let's consider the Deployment from above where we have 10 Pods running a container serving a machine learning model over REST. How do we reliably communicate with a server if the set of Pods running as part of the Deployment can change at any time? This is where the Service object enters the picture. A Kubernetes Service provides you with a stable endpoint which can be used to direct traffic to the desired Pods even as the exact underlying Pods change due to updates, scaling, and failures. Services know which Pods they should send traffic to based on labels (key-value pairs) which we define in the Pod metadata.
Note: This blog post does a nice job explaining how traffic is actually routed.
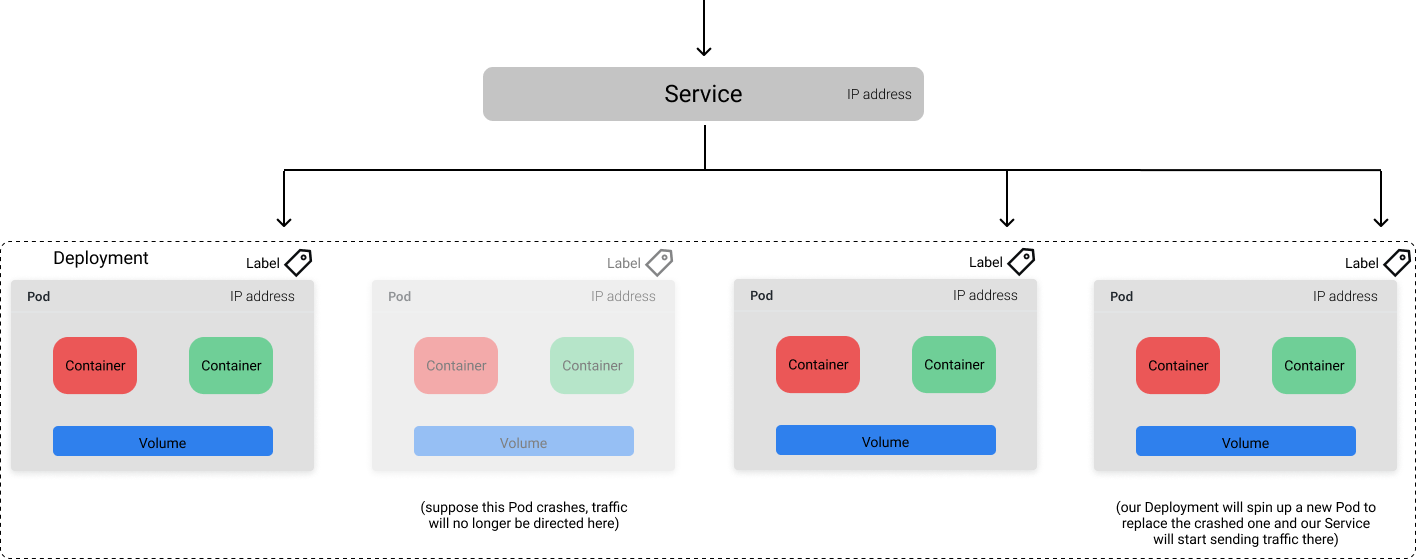
In this example, our Service sends traffic to all healthy Pods with the label app="ml-model".
The following YAML file provides an example for how we might wrap a Service around the earlier Deployment example.

Ingress
While a Service allows us to expose applications behind a stable endpoint, the endpoint is only available to internal cluster traffic. If we wanted to expose our application to traffic external to our cluster, we need to define an Ingress object.
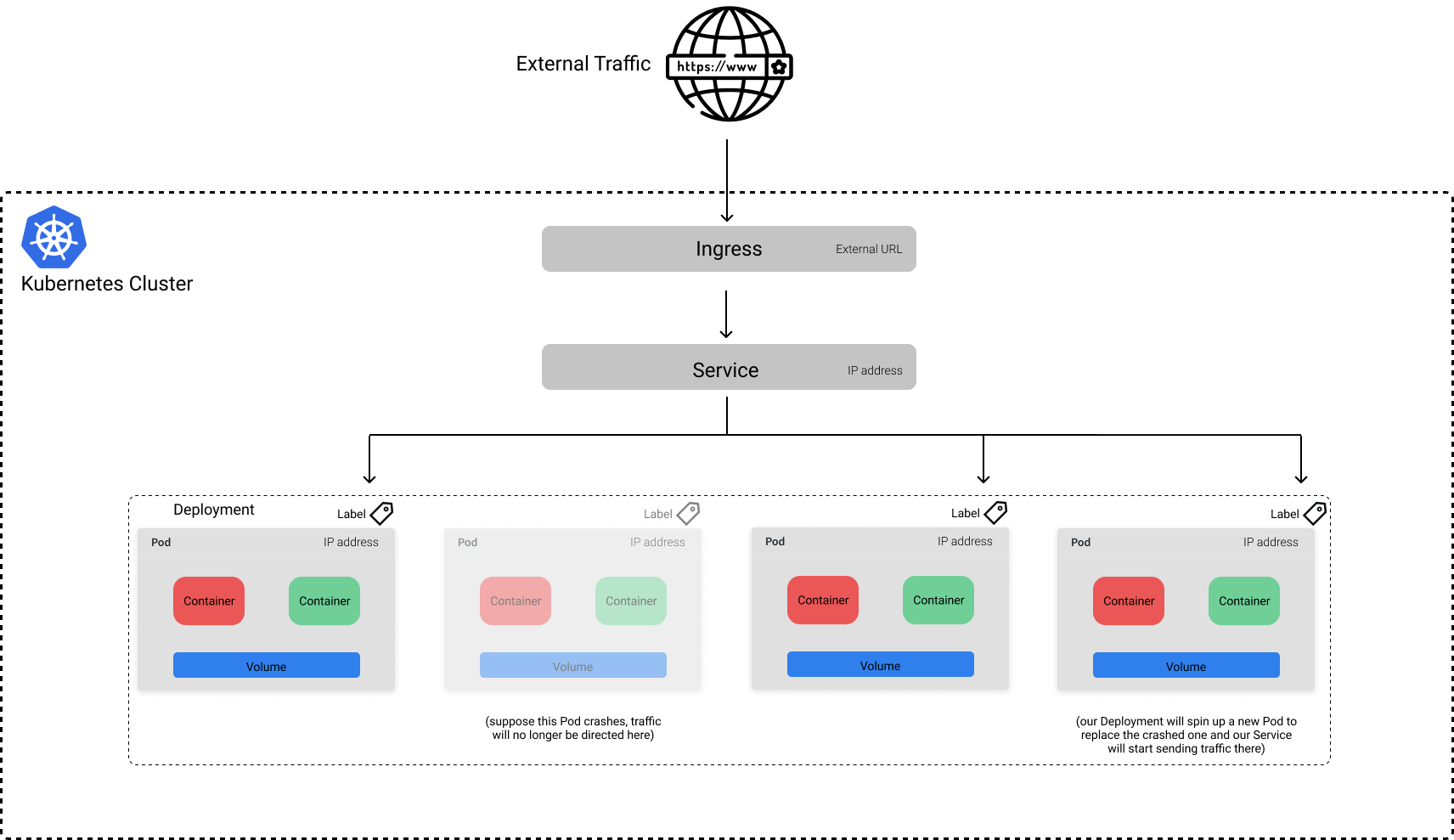
The benefit of this approach is that you can select which Services to make publicly available. For example, suppose that in addition to our Service for a machine learning model, we had a UI which leveraged the model's predictions as part of a larger application. We may choose to only make the UI available to public traffic, preventing users from being able to query the model serving Service directly.
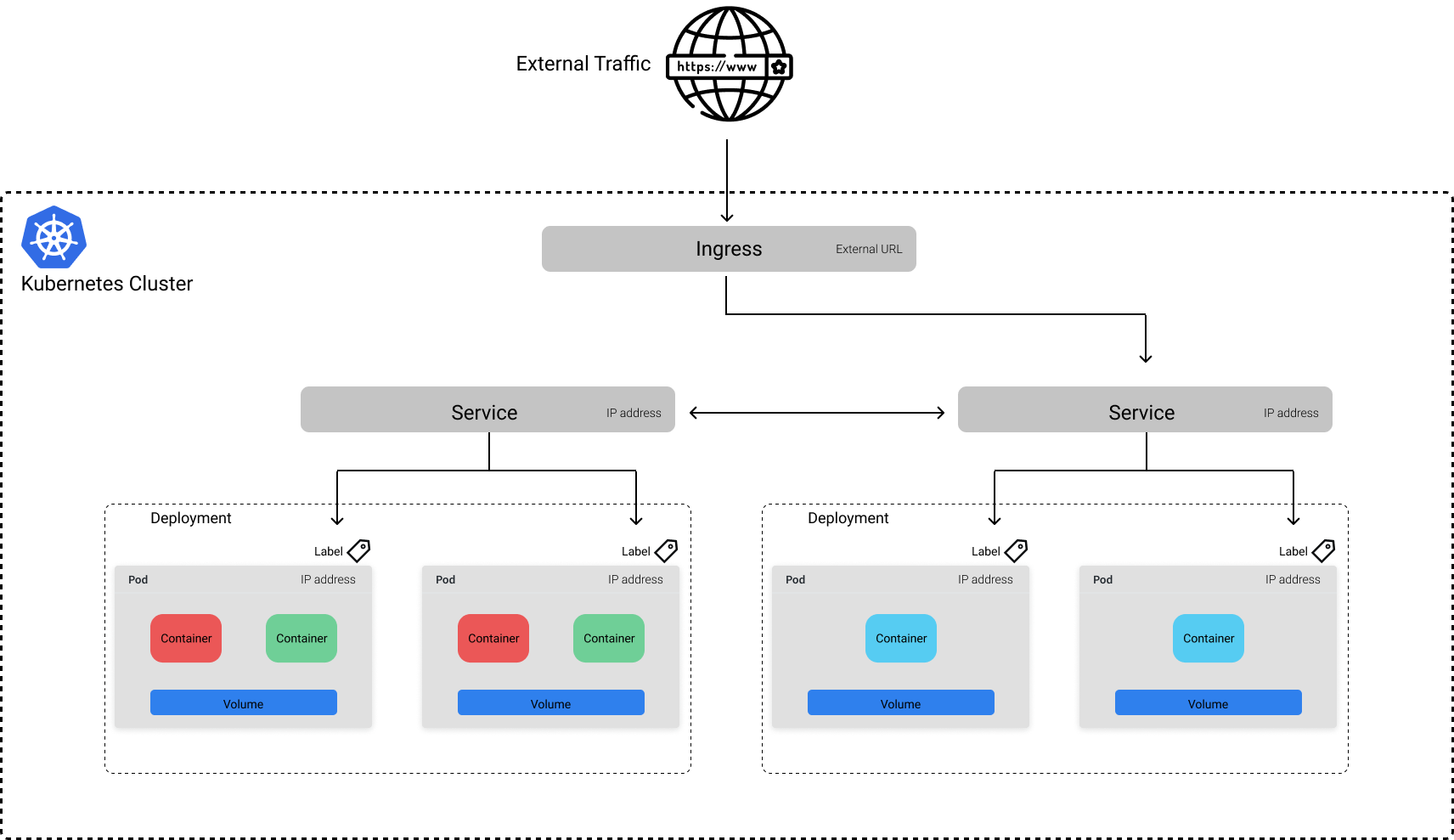
The following YAML file defines an Ingress object for the above example, making the UI publicly accessible.

Job
The Kubernetes objects I've described up until this point can be composed to create reliable, long-running services. In contrast, the Job object is useful when you want to perform a discrete task. For example, suppose we want to retrain our model daily based on the information collected from the previous day. Each day, we want to spin up a container to execute a predefined workload (eg. a train.py script) and then shut down when the training finishes. Jobs provide us the ability to do exactly this! If for some reason our container crashes before finishing the script, Kubernetes will react by launching a new Pod in its place to finish the job. For Job objects, the "desired state" of the object is completion of the job.
The following YAML defines an example Job for training a machine learning model (assuming the training code is defined in train.py).

Note: This Job specification will only execute a single training run. If we wanted to execute this job daily, we could define a CronJob object instead.
...and many more.
The objects discussed above are certainly not an exhaustive list of resource types available in Kubernetes. Some other objects that you'll most likely find useful when deploying applications include:
- Volume: for managing directories mounted onto Pods
- Secret: for storing sensitive credentials
- Namespace: for separating resources on your cluster
- ConfigMap: for specifying application configuration values to be mounted as a file
- HorizontalPodAutoscaler: for scaling Deployments based on the current resource utlization of existing Pods
- StatefulSet: similar to a Deployment, but for when you need to run a stateful application
How? The Kubernetes control plane.
By this point, you're probably wondering how Kubernetes is capable of taking all of our object specifications and actually executing these workloads on a cluster. In this section we'll discuss the components that make up the Kubernetes control plane which govern how workloads are executed, monitored, and maintained on our cluster.
Before we dive in, it's important to distinguish two classes of machines on our cluster:
- A master node contains most of the components which make up our control plane that we'll discuss below. In most moderate-sized clusters you'll only have a single master node, although it is possible to have multiple master nodes for high availability. If you use a cloud provider's managed Kubernetes service, they will typically abstract away the master node and you will not have to manage or pay for it.
- A worker node is a machine which actually runs our application workloads. It is possible to have multiple different machine types tailored to different types of workloads on your cluster. For example, you might have some GPU-optimized nodes for faster model training and then use CPU-optimized nodes for serving. When you define object specifications, you can specify a preference as to what type of machine the workload gets assigned to.
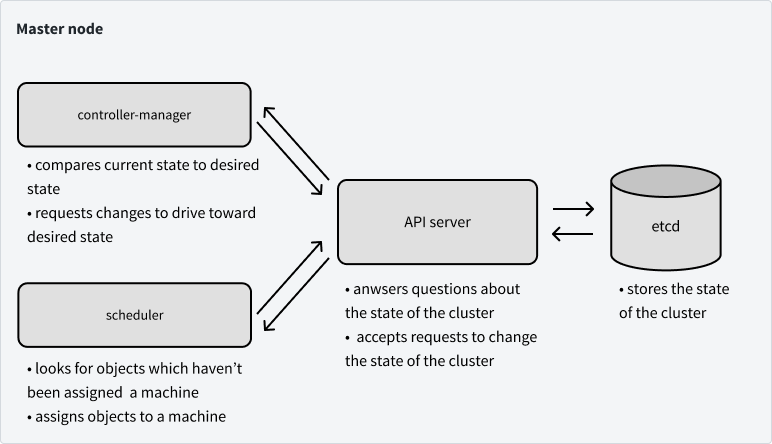
Now let's dive in to the main components on our master node. When you're communicating with Kubernetes to provide a new or updated object specification, you're talking to the API server.

More specifically, the API server validates requests to update objects and acts as the unified interface for questions about our cluster's current state. However, the state of our cluster is stored in etcd, a distributed key-value store. We'll use etcd to persist information regarding: our cluster configuration, object specifications, object statuses, nodes on the cluster, and which nodes the objects are assigned to run on.

Note: etcd is the only stateful component in our control plane, all other components are stateless.
Speaking of where objects should be run, the scheduler is in charge of determining this! The scheduler will ask the API server (which will then communicate with etcd) which objects which haven't been assigned to a machine. The scheduler will then determine which machines those objects should be assigned to and will reply back to the API server to reflect this assignment (which gets propagated to etcd).
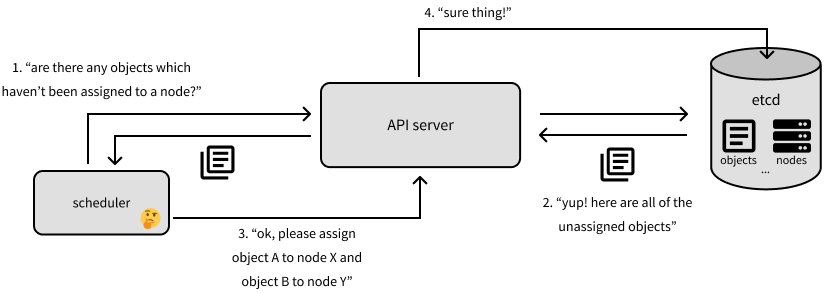
The last component on the master node that we'll discuss in this post is the controller-manager, which monitors the state of a cluster through the API server to see if the current state of the cluster aligns with our desired state. If the actual state differs from our desired state, the controller-manager will make changes via the API server in an attempt to drive the cluster towards the desired state. The controller-manager is defined by a collection of controllers, each of which are responsible for managing objects of a specific resource type on the cluster. At a very high level, a controller will watch a specific resource type (eg. deployments) stored in etcd and create specifications for the pods which should be run to acheive the object's desired state. It is then the controller's responsibility for ensuring that these pods stay healthy while running and are shut down when needed.
To summarize what we've covered so far...
Next, let's discuss the control plane components which are run on worker nodes. Most of the resources available on our worker nodes are spent running our actual applications, but our nodes do need to know which pods they should be running and how to communicate with pods on other machines. The two final components of the control plane that we'll discuss cover exactly these two concerns.
The kubelet acts as a node's "agent" which communicates with the API server to see which container workloads have been assigned to the node. It is then responsible for spinning up pods to run these assigned workloads. When a node first joins the cluster, kubelet is responsible for announcing the node's existence to the API server so the scheduler can assign pods to it.
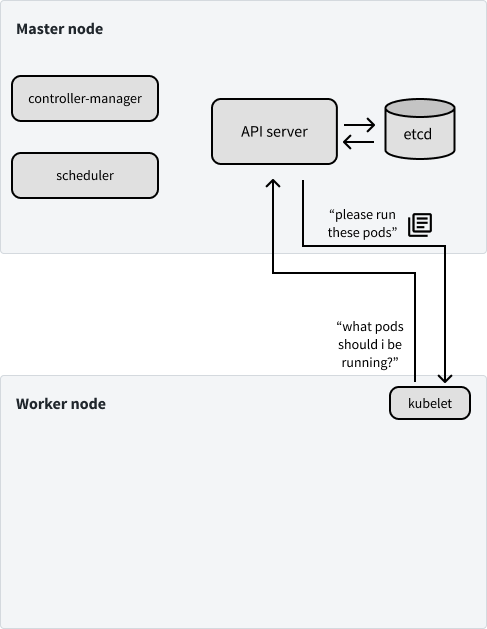
Lastly, kube-proxy enables containers to be able to communicate with each other across the various nodes on the cluster. This component handles all the networking concerns such as how to forward traffic to the appropriate pod.
Hopefully, by this point you should be able to start seeing the whole picture for how things operate in a Kubernetes cluster. All of the components interact through the API server and we store the state of our cluster in etcd. There are various components which write to etcd (via the API server) to make changes to the cluster and nodes on the cluster listen to etcd (via the API server) to see which pods it should be running.

The overall system is designed such that failures have minimal impact on the overall cluster. For example, if our master node went down, none of our applications would be immediately affected; we would just be prevented from making any further changes to the cluster until a new master node is brought online.
When should you not use Kubernetes?
As with every new technology, you'll incur an overhead cost of adoption as you learn how it works and how it applies to the applications that you're building. It's a reasonable question to ask "do I really need Kubernetes?" so I'll attempt to provide some example situations where the answer might be no.
- You can run your workload on a single machine. (Kubernetes can be viewed as a platform for building distributed systems, but you shouldn't build a distributed system if you don't need one!)
- Your compute needs are light. (In this case, the compute spent on the orchestration framework is relatively high!)
- You don't need high availability and can tolerate downtime.
- You don't envision making a lot of changes to your deployed services.
- You already have an effective tool stack that you're satisfied with.
- You have a monolithic architecture and don't plan to separate it into microservices. (This goes back to using the tool as it was intended to be used.)
- You read this post and thought "holy shit this is complicated" rather than "holy shit this is useful".
Gratitude
Thank you to Derek Whatley and Devon Kinghorn for teaching me most of what I know about Kubernetes and answering my questions as I've been trying to wrap my head around this technology. Thank you to Goku Mohandas, John Huffman, Dan Salo, and Zack Abzug for spending your time to review an early version of this post and provide thoughtful feedback. And lastly, thank you to Kelsey Hightower for all that you've contributed to the Kubernetes community - your talks have helped me understand the bigger picture and gave me confidence that I could learn about this topic.
Resources
Here are some resources that I found to be useful when learning about Kubernetes.
Blogs
- Julia Evans - Reasons Kubernetes is cool
- Julia Evans - A few things I've learned about Kubernetes (Julia's zines were a big inspiration for my visuals explaining the Kubernetes control plane)
- Jessie Frazelle - You might not need Kubernetes
- Matt Rogish - Is Kubernetes Overkill?
- Major Trends in the 2019 Data & AI Landscape
- Introduction to cloud-native applications and defining cloud native
- Kubernetes Best Practices 101
Videos
- Kelsey Hightower - Kuberenetes for Pythonistas discusses the motivation for Kubernetes and provides an example of running a Python application.
- Kubernetes by Kelsey Hightower introduces the core components of Kubernetes and how they work together, with the API server at the core.
- Kubernetes The Easy Way! presents a developer-centric workflow for building products and leveraging Kubernetes as the infrastructure.
- Kubernetes in Real Life - Ian Crosby
- Kubernetes Design Principles: Understand the Why - Saad Ali, Google
- Kubernetes Deconstructed: Understanding Kubernetes by Breaking It Down - Carson Anderson, DOMO
- From COBOL to Kubernetes: A 250 Year Old Bank's Cloud-Native Journey - Laura Rehorst
Books